p1-sentiments
EECS 285 Project 1: Tweet Sentiments
Project Due Friday, 17 Sep 2021, 8pm
In this project, you will analyze Twitter data to determine how people within a geographical region feel about a topic compared to people outside that region. You will define basic data structures for locations and tweets, assign sentiments to a tweet based on the words in the contains, and aggregate tweets according to location to determine the average sentiment within and outside a region.
The purpose of this project is to gain some basic literacy of Java, involving both reading and writing Java code. Unlike future projects, the classes and methods you’ll be writing are fully specified. You are required to adhere to the specifications here and in the starter code.
Authors
The project was written by Amir Kamil for EECS 285. It is based on the Twitter Trends project in the Composing Programs text.
The Twitter data in this project consists of actual tweets sent in late August and early September 2011.
Table of Contents
- Project Roadmap
- The
LocationClass - The
TweetClass - The
TweetAnalyzerClass - The
TweetSentimentMainClass - Requirements and Restrictions
Project Roadmap
This is a big-picture view of what you’ll need to do to complete this project. Most of the pieces listed here also have a corresponding section later on in the spec that goes into more detail.
This project will be autograded for correctness, and the correctness portion is worth 100% of your project grade. We will not hand grade this project.
We will also run automated style and programming-practice checks on your code. However, these checks will not be worth any points on this project.
You must work alone for this project.
Download the starter code
The starter code is available at https://eecs285.github.io/p1-sentiments/starter-files.zip. The following files are included:
| File(s) | Description |
|---|---|
Sentiments.java |
Data structure that maps words to sentiments |
TweetReader.java |
Data structure that holds tweet data read from a file |
TweetAnalyzer.java |
Class that analyzes tweet sentiments. You will need to complete this class. |
TweetSentimentMain.java |
Main driver for tweet-sentiment analysis |
Test.java |
Basic tests for Location and Tweet clases |
Test.correct |
Correct output from running Test |
data/ |
Directory containing sentiment data (sentiments.csv) and tweet data (*.txt) |
obama.correct soup.correct texas.correct |
Correct output from running sentiment analysis on obama.txt, soup.txt, and texas.txt |
Extract the files to a temporary directory.
Set up your project
Follow the setup tutorial to set up your project.
Your Java files should all be in a package with the structure
eecs285.proj1.<uniqname>, where <uniqname> is your uniqname. For
example, I would put the following package directive at the top of
each .java file:
package eecs285.proj1.akamil;
You will need to modify each of the starter files so that they have the correct package directive at the top.
Familiarize yourself with the starter code
Read through the starter code to understand what classes and methods are available. You need only read through the documentation; you do not have to understand how the starter code works.
Understand what you need to write
Read through the rest of the specification to determine what classes you must complete or write from scratch.
Implement and test your classes and methods
Implement the required classes and methods. Start by writing stubs, empty implementations (or just a trivial return for non-void methods) of the methods you need to write, so that the code will compile. Then write the actual implementation of each method, testing along the way.
In addition to the provided tests, you should write your own, as the tests in the starter code do not fully test the code you will write.
Submit
Submit the following files to the autograder.
Location.javaTweet.javaTweetAnalyzer.java
Do not submit Test.java or TweetSentimentMain.java. We will
use our own versions of these files, so make sure that your
implementation does not require them to be modified.
As per course policy, we will grade your last submission to the autograder. It is your responsibility to ensure that your last submission is complete.
The Location Class
The Location class represents a geographical location, with a given
latitude and longitude. You will need to create a file
Location.java. Place the appropriate package directive at the top
and define a public class Location. This class should have the
following fields (data members):
- A
doubleto represent the latitude. - A
doubleto represent the longitude.
It should also have the following public methods:
- A constructor that takes in a latitude and longitude and initializes the fields. You do not have to do any error checking on latitude or longitude values.
- A method
getLatitude()that returns the latitude of the location. - A method
getLongitude()that returns the longitude of the location. -
A
toString()method with the following signature:@Override public String toString();This method should return a string representation of the location, in the following format:
[<latitude>, <longitude>]For instance, the
Locationwith latitude 42.28 and longitude -83.75 would return the string:"[42.28, -83.75]" -
A method with the following signature:
public boolean isWithin(Location lowerBound, Location upperBound);This method should return true if the location’s latitude is between that of
lowerBoundandupperBound, inclusive, and the location’s longitude is also between that oflowerBoundandupperBound. It should return false otherwise.
Once you have written the Location class, you should test it to make
sure it is correct. We have provided a basic test as part of
Test.java. You will need to write stubs for Tweet.java in order
for the code to compile.
The Tweet Class
The Tweet class represents an individual tweet, keeping track of both
the location where the tweet originated and the content of the tweet.
You will need to create a file Tweet.java, with the appropriate package
directive and a public class Tweet. The class should have the following
fields:
- A
Stringto represent the content of the tweet. - A
Locationto represent the geographical location of the tweet.
You will need to define the following public methods:
- A constructor that takes in a
Stringrepresenting the content, adoublelatitude, and adoublelongitude. - A method
getText()that returns the content of the tweet. - A method
getLocation()that returns the location of the tweet. -
A
toString()method that returns a string representation of the tweet. This should just be the location and content separated by a space. For example:"[42.28, -83.75] i love my job. #winning" -
A method with the following signature:
public ArrayList<String> getWords();You will need an import statement after the package directive:
import java.util.ArrayList;The
getWords()method should return a list of the individual words in the tweet. For the purposes of this project, a word is a consective sequence of ASCII letters, i.e. characters in the range[a, z]or[A, Z]. You can use thecharAt()method ofStringto obtain an individual character, and then you can compare the character to the literals'a','z','A','Z'to determine if it falls in either range. For the tweet above, the individual words are"i","love","my","job", and"winning".You will need to construct individual
Strings for each word. You can use the+or+=operators to construct aStringincrementally.Read through the documentation for
ArrayListto determine how to use it. (We are usingStringin place of the typeEin the documentation.)
The TweetAnalyzer Class
The TweetAnalyzer class analyzes the sentiment of tweets. Part of
the class is already written for you. You will need to fill in the
implementation of the following methods:
-
computeSentiment(), which computes the sentiment of an individual tweet. You will need to retrieve the words from the tweet and then compute the average sentiment of words in the tweet. Ignore any words with a sentiment of zero. Read through the documentation for theSentimentsclass to determine how to obtain the sentiment of a word.The return type of
computeSentiment()isDouble, a “boxed” version ofdoublethat is an object rather than a primitive. This allows us to returnnullfor tweets that do not have a word with a sentiment, which is distinct from a tweet with both positive and negative words that average out to a sentiment of zero. -
averageSentimentWithin()computes the average sentiment of tweets within the given geographic area. It should ignore tweets that have no sentiment (those for whichcomputeSentiment()returnsnull) and tweets outside the geographic area.If there are no tweets with sentiment within the geographic area, the method should print out the following:
No tweets with sentimentThere should be two spaces before the word
No, and the print should end with a newline.If there are tweets with sentiment within the geographic area, the method should print out the following:
Average sentiment over <count> tweets: <sentiment>There should be two spaces before the word
Average, and the print should end with a newline.<count>should be the number of tweets within the geographic area that have sentiment.<sentiment>should be the average sentiment of those tweets, rounded to four digits after the decimal: use theroundedString()method to convert adoubleto the appropriate rounded string. -
averageSentimentOutside()computes the average sentiment of tweets outside the given geographic area. It should behave the same asaverageSentimentWithin(), except that it considers the tweets outside the area rather than within it.
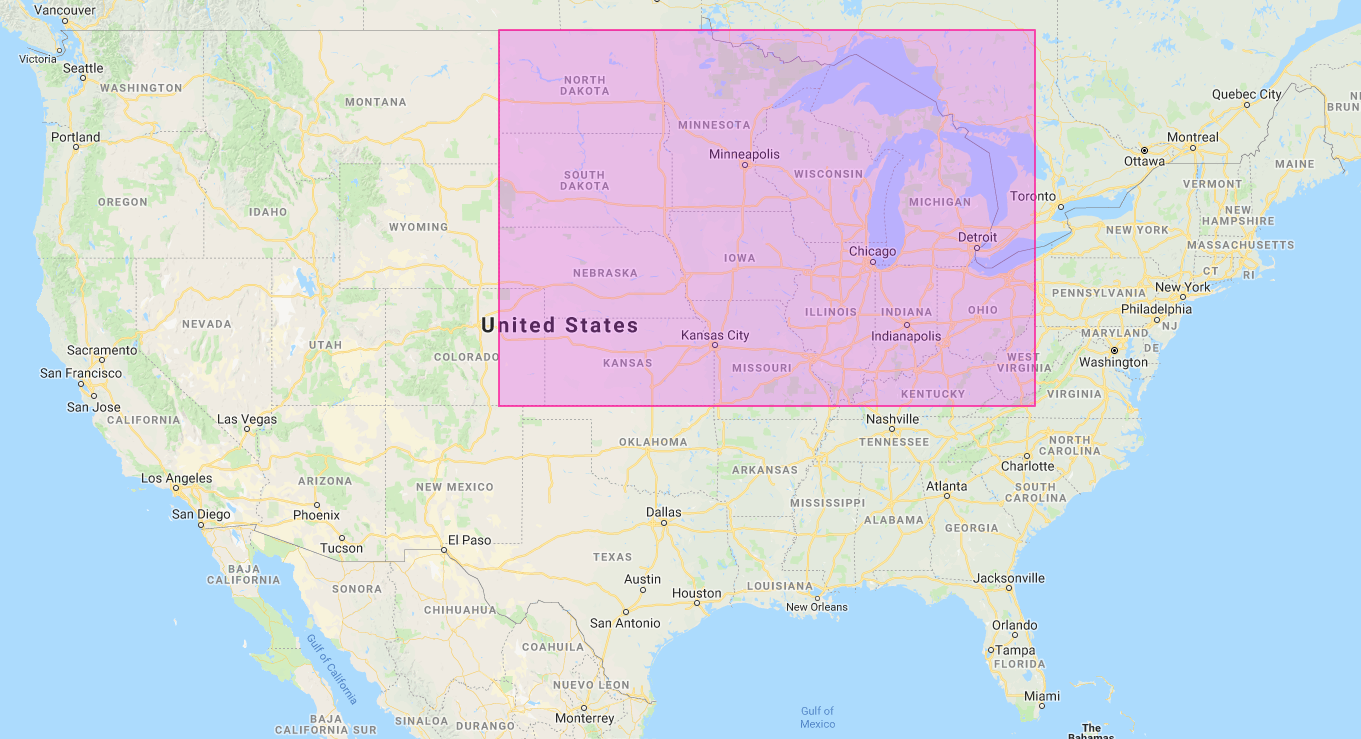
The TweetSentimentMain Class
The TweetSentimentMain class is the top-level driver for the
analysis. Given a tweet file, it computes the average sentiment within
an approximation of the Midwest region, as well as the average
sentiment outside of it:
Along with changing the package directive, you will need to set the
UNIQNAME constant to be your uniqname, so that the code can load
data files from the proper location. Initially, the TWEET_FILE
constant is set to "soup.txt", so that the program analyzes tweet
data concerning “soup”. You can change the constant to one of the
other data files in the data/ directory, or you can specify the
tweet file at the command line:
$ java eecs285.proj1.akamil.TweetSentimentMain obama.txt
(Of course, you should replace akamil with your own uniqname.)
You can also specify the command-line arguments in IntelliJ, as described in the setup tutorial.
We have provided correct output files for a subset of the tweet-data
files. For instance, the following is the result of running the
analysis on obama.txt, which contains tweets with the word “obama”
in them:
Tweet file: obama.txt
Location boundary: [37.0, -104.05] to [49.0, -80.517]
Sentiment within boundary:
Average sentiment over 129 tweets: 0.0391
Sentiment outside boundary:
Average sentiment over 627 tweets: 0.0088
Given the dataset, it appears that people within the Midwest had a slightly higher opinion of “obama” than those outside the Midwest. Perhaps because President Obama is from Chicago?
Requirements and Restrictions
-
You must follow the specifications in here and in the starter code exactly. This project will be autograded, so any deviation from the specifications will likely result in a 0.
-
You may not use any Java library classes except
ArrayList,Double, andString. -
You may not and any fields to your classes, other than those described in the spec.
-
You may add private helper methods, but you may not add any non-private methods.